Image Labelling with ChatGPT Vision + Magic: The Gathering

GPT-4 with Vision, or gpt-4-vision-preview in the API, is a new(ish) model from OpenAI that can answer questions about images. I'll take a look at what it can do, show you how to the generated descriptions for easy full text search, and share the code for everything.
In order to get a sense of working with vision on a non-trivial data set, I decided that it would be fun to generate descriptions of all of the unique artwork in Magic: The Gathering and make them easily searchable. There are 23976 different pieces of art in the game. With this data you can finally build a deck with only cards featuring artwork of people yelling.






Artwork from Magic: The Gathering Cards Labelled by ChatGPT Vision as "Yelling"
Step 1 - Gather Your Images
I could access this data through a nice Rest API provided by Scryfall, but they also have bulk data sets that I can download to be polite. I saved the "unique artwork" file since it has one record per artwork, and the docs say that the "chosen cards promote the best image scans."
Each "card" contains meta data relevant to the game such as colour, original printing date, expansion set name, and links to images of both the full card and a crop of just the art. We will target these art crops.
I set up a database in mongo, and inserted all of the artwork data into it. For this experiment, I have a record for each unique artwork in Magic: The Gathering. I created a database called card_art and a collection called mtg in Mongo Atlas to hold the data. For the amount of records we have (approx 24k), an insertMany worked just fine.
import uniqueArtwork from './data/unique-artwork-20240304100235.json';
const artwork = uniqueArtwork["cards"];
await mongo.client.db('card_art').collection('mtg').insertMany(artwork);I did a little massaging on the input data to make it valid json and easier to import
Step 2 - Feed Images to ChatGPT Vision
In order to get descriptions of the art, I simply tell ChatGPT Vision to Generate a detailed description of the scene in this image. In typescript it looks like this:
const response = await this.openai.chat.completions.create({
model: "gpt-4-vision-preview",
max_tokens: 384,
messages: [
{
role: "user",
content: [
{
type: "text",
text: "Generate a detailed description of the scene in this image." },
{
type: "image_url",
image_url: {
"url": "<IMAGE_URL>",
},
},
],
},
],
});
console.log('description: ', response.choices[0].message.content);ChatGPT will happily accept urls and fetch the images itself. This can save a lot of time downloading and re-uploading images if your source material is already stored online somewhere.
With this code, I can generate a description of an individual image. Here's a snippet of some output:

...He is wearing a pair of goggles pushed up onto his forehead, suggesting a readiness for harsh conditions or a need for protective eyewear, perhaps for flying or navigating through treacherous environments. He holds a staff in one hand that is topped with a bright, glowing orb, which could be a source of light or magic...The color palette is a mix of cool blues and grays, with the orb providing a contrasting warm glow, highlighting the dwarf and adding depth to the scene....
Of course, I don't just want to know that Powerstone Engineer wears goggles – I want to find all cards that feature goggles. In order to search all of the art that ChatGPT is seeing, I'll need to store the text descriptions into the database. I refactored the vision generation into a ChatGPTProvider, and wrote some code that will get a description for one record and save it to a new field called description in the database:
const chatGPT = new ChatGPTProvider();
const collection = mongo.client.db('card_art').collection('mtg');
const record = await collection.findOne({ _id });
const crop = record.image_uris.art_crop;
const description = await chatGPT.getImageDescription(crop);
await mongo.client.db('card_art').collection('mtg').updateOne(
{ _id: record._id },
{ $set: { description } }
);We will need to create an index to use the full $search functionality of the mongo aggregation framework against the descriptions.
Step 3 - Index Descriptions in Mongo Atlas
Now that we have saved one description, we can head over to Atlas and create a search index on that field. In the Atlas UI, create a new index and use a definition like the following since the new field we set is called "description".
{
"mappings": {
"dynamic": true
},
"storedSource": {
"include": [
"description"
]
}
}This will ensure that we only index the description field and do not apply storage intensive search indexing to every field in our collection.
Now that we have an index set up, any new records inserted will automatically be indexed for searching. We will loop over all the images in our database and generate/save descriptions for each saving as we go. This is essentially a large migration script, so we will want to make sure it handles failure gracefully. It's unlikely we can get a perfect run through all 23 thousand images without experiencing some kind of failure. If we need to restart, we don't want to lose any of our progress. In pseudo-code:
- Create a cursor that selects cards without descriptions
- While that cursor still has a next document:
- Read the next document
- Generate a description for the image
- Save that description
- Close the cursorIf this script fails at any point, we can restart from the beginning since we will get a new cursor that only include images that do not have descriptions yet
pm2 to automatically restart the script.I checked the script into a repo (below). It's geared towards Magic art but is generic enough that you could easily use this to enhance any data set that contains images.
 rogersnick
rogersnickScript for Generating and Saving MTG Art Descriptions
Step 4 - Search Full Text Descriptions
Since we already defined an index, the new descriptions that we save will already be searchable. In order to query the full text descriptions, we can use the mongo aggregation framework with a $search stage. Note that $search must always be the first stage in a any mongo aggregation.
{ $search:
{
index: 'default',
text: {
query: 'stained glass',
path: 'description'
}
}
}This stage will match and return documents based on the how closely their descriptions match the phrase stained glass - here's a quick look at the top six results:






Searching for MTG art that contains "Stained Glass"
This search is based entirely on the descriptions that ChatGPT came up with! At the time of writing I have indexed cards from the most recent three sets as well as a handful of others from testing.
Cost Analysis / Usage Look In
Describing an image (on average, using the max tokens of 384 that I applied) seems to cost about a penny each. Indexing the full set will take more time and money, but for this experiment I'm tapping out at $50. If you are interested in this data or a collaboration, do reach out.
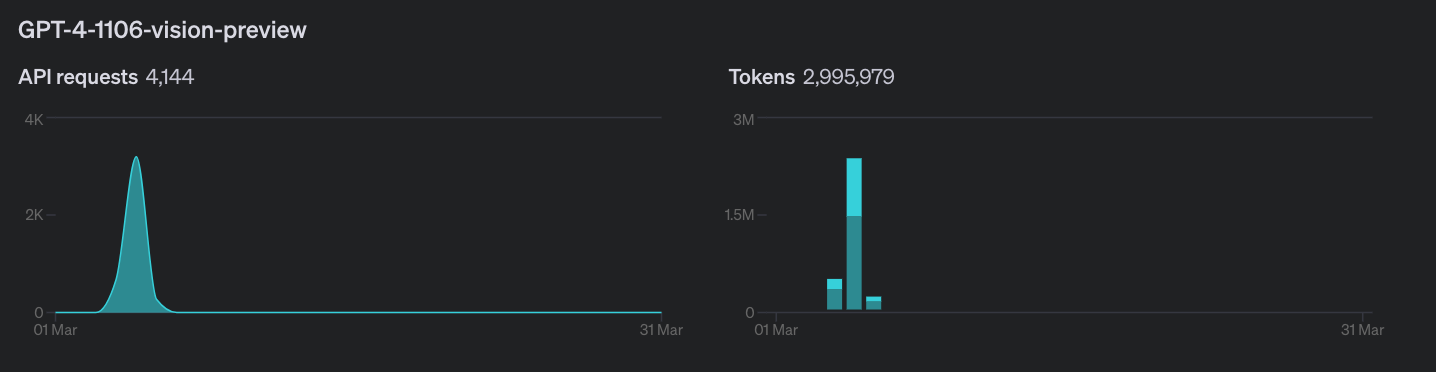
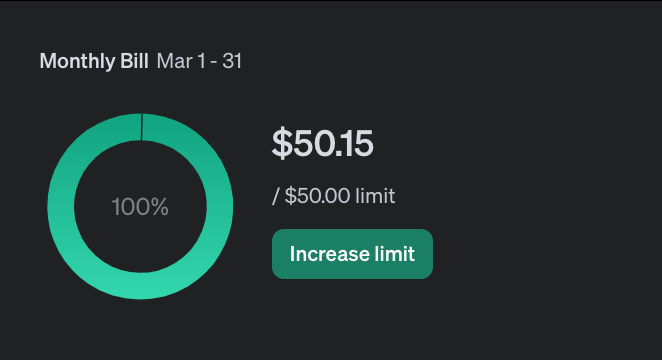
As of the time of writing, I have used 4k requests, 3M tokens, and incurred a cost of $50.15 (currently $0.15 over budget). This represents over 2500 cards indexed. reaching back from present day to Kamigawa: Neon Dynasty.
Occasionally ChatGPT will return an apology and refuse to generate an image. It seems to sometimes think I am trying to trick it into describing people in some kind of nefarious way. As a Canadian, I appreciate the apologies, but it's worth noting that over the course of generation, about 5% of requests resulted in something containing the words "Sorry" or "Unable (to generate image)". Factor that in if you plan to use Vision to augment some images yourself.
Currently Indexed - all sets from present day back to Kamigawa: Neon Dynasty.
If this experiment was interesting for you, then subscribe! If you already have, share it with someone else who might enjoy it.